

Amazon Textract
Easily extract text and data for virtually any document.

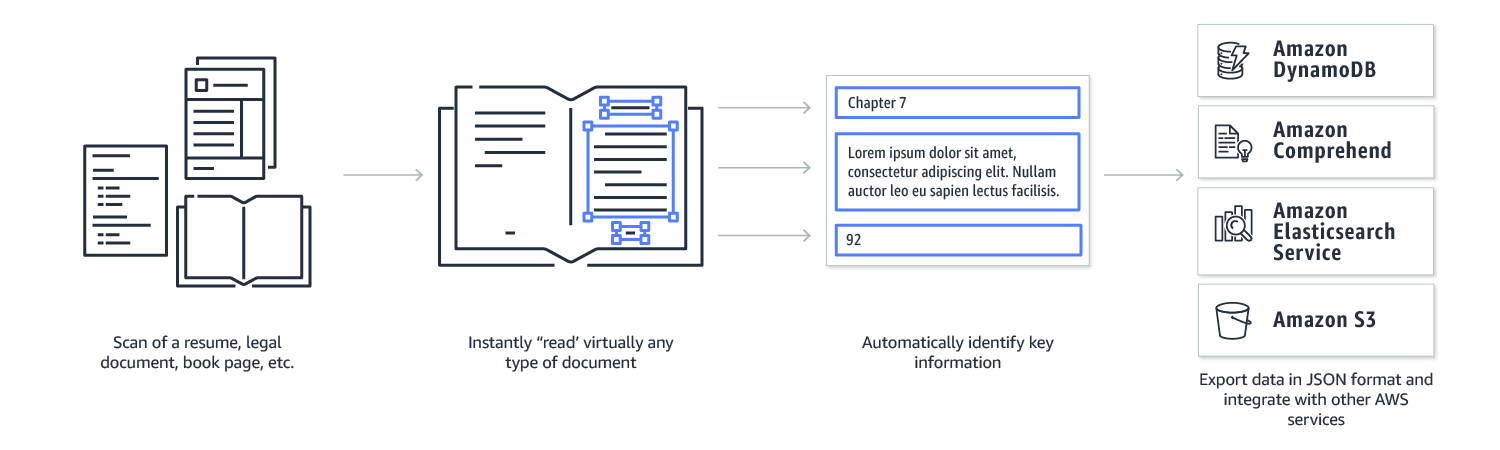
Amazon Textract is a fully managed machine learning service that automatically extracts text and data from scanned documents that goes beyond simple optical character recognition (OCR) to identify, understand, and extract data from forms and tables.
Many companies today extract data from scanned documents, such as PDF's, tables and forms, through manual data entry (that is slow, expensive and prone to errors), or through simple OCR software that requires manual configuration which needs to be updated each time the form changes to be usable.
To overcome these manual processes, Textract uses machine learning to instantly read and process any type of document, accurately extracting text, forms, tables and, other data without the need for any manual effort or custom code.
With Textract you can quickly automate manual document activities, enabling you to process millions of document pages in hours. Once the information is captured, you can take action on it within your business applications to initiate next steps for a loan application, tax document, enrollment form or medical claims processing. Additionally, you can create smart search indexes, or add in human reviews with Amazon Augmented AI to review nuanced or sensitive data.
Amazon Textract Benefits

Extract structured & unstructured data quickly and accurately
Amazon Textract uses artificial intelligence to “read” documents as a person would, to extract not only text but also tables, forms, and other structured data without configuration, training, or custom code. Amazon Textract automatically detects a document’s layout and the key elements on the page, understands the data relationships in any embedded forms or tables, and extracts everything with its context intact.
Go beyond simple Optical Character Recognition (OCR)
Amazon Textract uses OCR technology to identify form labels and values and extracts
information from tables without compromising the structure at a low cost. You only pay forwhat you use and there are no upfront commitments or long-term contracts.


Security & Compliance
Textract can be used for workloads that are subject to Service Organization Control (SOC) compliance, International Organization for Standardization (ISO) compliance, PCI, HIPAA, and GPDR. Customers in finance, healthcare, and other industries can get insights into the security processes and controls that protect their customer data. Textract also supports Amazon Virtual Private Cloud (Amazon VPC) endpoints via AWS PrivateLink enabling customers to securelyinitiate API calls to Amazon Textract from within their VPC and avoid using the public internet.
Easily implement human reviews
Amazon Textract is directly integrated with Amazon Augmented AI (Amazon A2I) so you can easily implement human review of text extracted from documents. You can build-in human reviews to manage nuanced or sensitive workflows that require human judgement to get high confidence predictions or to audit predictions on an on-going basis.

Amazon Textract Benefits
Optical Character Recognition (OCR)
Because Amazon Textract identifies data types and form labels automatically, it’s easy to maintain compliance with information controls. For example, an insurer could use Amazon Textract to feed a workflow that automatically redacts personally identifiable information (PII) for their review before archiving claim forms by automatically recognizing the important key-value pairs that require protection.
Form Extraction
Amazon Textract enables you to detect key-value pairs in document images automatically so that you can retain the inherent context of the document without any manual intervention. A key-value pair is a set of linked data items. For instance, on a document the field “First Name” would be the key and “Jane” would be the value. This makes it easy to import the extracted data into a database or to provide it as a variable into an application. With traditional OCR solutions, keys and values are extracted as simple text. The relationship between them is lost unless hard-coded rules are written and maintained for each form.
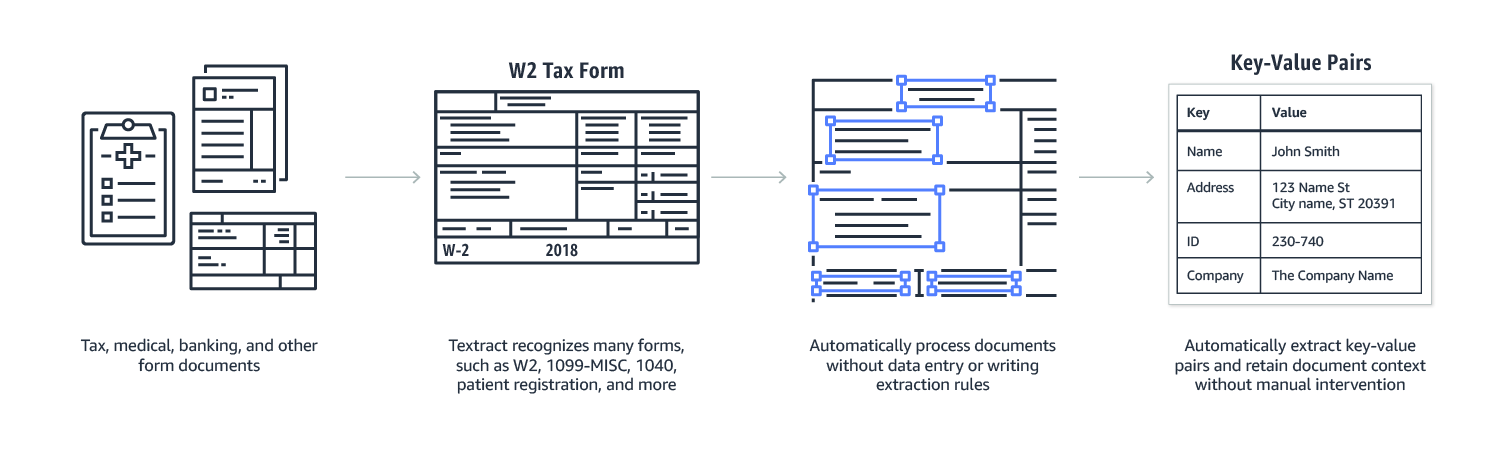
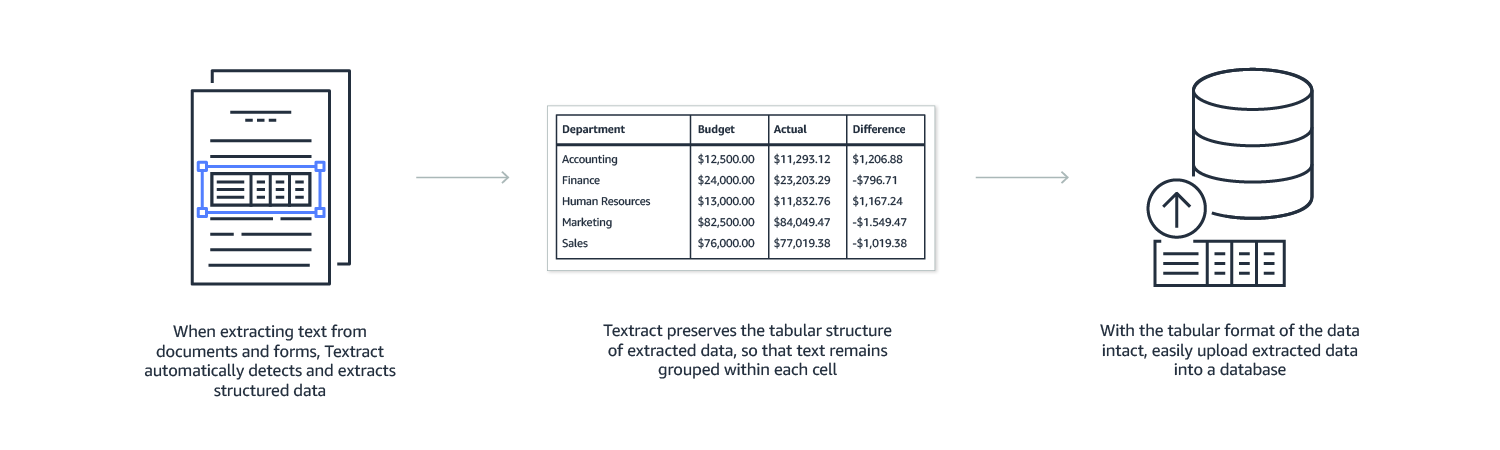
Table Extraction
Amazon Textract preserves the composition of data stored in tables during extraction. This is helpful for documents that are largely composed of structured data, such as financial reports or medical records that have column names in the top row of the table followed by rows of individual entries. You can use this feature to automatically load the extracted data into a database using a pre-defined schema. For example, rows of item numbers and quantities in an inventory report will retain their association to easily increment item totals in an inventory management application.
Bounding Boxes
Amazon Textract preserves the composition of data stored in tables during extraction. This is helpful for documents that are largely composed of structured data, such as financial reports or medical records that have column names in the top row of the table followed by rows of individual entries. You can use this feature to automatically load the extracted data into a database using a pre-defined schema. For example, rows of item numbers and quantities in an inventory report will retain their association to easily increment item totals in an inventory management application.
Adjustable Confidence Thresholds
When information is extracted from documents, Amazon Textract returns a confidence score for everything it identifies so that you can make informed decisions about how you want to use the results. For instance, if you are extracting information from tax documents and want to ensure high accuracy, then you can create business logic to flag any extracted information with a confidence score lower than 95% to be reviewed by a human. However, you may choose a lower threshold for other types of documents where the consequences of an error have little to no negative consequences like processing resumes or digitizing archived documents.
Built-in Human Review Workflow
Amazon Textract is directly integrated with Amazon Augmented AI (Amazon A2I) so you can easily implement human review of text extracted from documents. Many text extraction applications require humans to review low confidence predictions to ensure the results are correct. For example, extracting information from scanned mortgage application forms can require human review in some cases, such as when the quality of the document rendering is poor. But building human review systems can be time consuming and expensive because it involves implementing complex processes or “workflows”, writing custom software to manage review tasks and results, and in many cases, managing large groups of reviewers. Amazon A2I provides built-in human review workflows for text extraction from documents, which allows predictions from Amazon Textract to be reviewed easily. You can choose a confidence threshold for your application, and all predictions with a confidence below the threshold are automatically sent to human reviewers for validation. You can also specify which key/ value pairs should be sent for human review. Lastly, you can also configure A2I to send randomly selected documents for human review. With Amazon A2I, you can use a pool of reviewers within your own organization, or you can access the workforce of over 500,000 independent contractors who are already performing machine learning tasks through Amazon Mechanical Turk. You can also make use of workforce vendors that are pre-screened by AWS for quality and adherence to security procedures. To learn more about implementing human review workflows, see the Amazon A2I website and Amazon A2I Integration with Amazon Textract in the developer guide.
Use Cases
Build automated document processing workflows
Amazon Textract can provide the inputs required to automatically process forms without human intervention. For example, banks can automate loan applications using Amazon Textract. The information contained in the document could be used to initiate all of the necessary background and credit checks to approve the loan so that customers can get instant results of their application rather than having to wait several days for manual review and validation.

Maintain compliance in document archives
Because Amazon Textract identifies data types and form labels automatically, it’s easy to maintain compliance with information controls. For example, an insurer could use Amazon Textract to feed a workflow that automatically redacts personally identifiable information (PII) for their review before archiving claim forms by automatically recognizing the important keyvalue pairs that require protection.

Build automated document processing workflows
Amazon Textract can provide the inputs required to automatically process forms without human intervention. For example, banks can automate loan applications using Amazon Textract. The information contained in the document could be used to initiate all of the necessary background and credit checks to approve the loan so that customers can get instant results of their application rather than having to wait several days for manual review and validation.




