

How to backup S3 object with AWS S3 Cross region replication

Amazon Simple Storage Service (Amazon S3) is a highly scalable and fast, cloud storage service. This service is like a hard drive on the cloud with essentially infinite storage space. As such, it can be leveraged as a primary storage for some use case, backup for others, as an archive for data and applications, and so on.
Nowadays, the world is moving to SaaS services and thus the cloud storage is a vital part of the SaaS solutions. This also means that the availability and durability are the key factors to be considered to avoid any degradation, loss, or corruption of data.
Amazon S3 guarantees four nines availability (99.99%), and even eleven nines (99.999999999%) availability, of your data and uptime of 99.9%.
Data stored on an S3 bucket inside a region is replicated across multiple servers, enabling high data availability on a region level. If there are issues on a region level, the data will be unavailable, and the application that uses S3 storage might experience downtime. To prevent such unexpected downtime for the business-critical applications, we can use an Amazon S3 feature called Cross-Region Replication.

Cross-Region Replication
In general, replication is a process of copying and in S3 it refers to the process of copying data from one S3 bucket to another bucket and essentially in an automatic manner, without affecting anything else. S3 replication helps to replicate data across buckets, either in the same or in a different region and this is known as S3 Cross Region Replication. Amazon S3 also maintains the metadata, thus, allowing users to store information such as origin, modifications, etc. of the data source and monitor any changes.
The Cross-region replication feature enables automatic and asynchronous copy of the data from one destination bucket to another, located in one of the other AWS regions. Once it is enabled, every object uploaded to a particular S3 bucket is automatically replicated into a predefined destination bucket in another AWS region.
Even the name and metadata of the replicated copies of the objects in the destination bucket are identical to those in the source bucket. However, the replication is not transitive.
There is a flexibility to choose only certain objects to be replicated and restrict others using a prefix notation. However, if there are objects already in the bucket, only the new ones will be replicated as it needs a trigger to replicate and uploading or modifying an object acts as that trigger. Also, it must be noted that the bucket replication cannot be done within the same regions.
We can setup lifecycle policy rules inside the destination bucket to delete older versions of the data, or, store them to Amazon Glacier and so on. Moreover, to have those actions replicated at the source, we need to set up the same Lifecycle Policies on the source bucket.
If the objects are encrypted using AWS S3 Managed Encryption Key, those objects are replicated in a manner that encrypts the copy using the same key. However, the objects that were encrypted using customer-provided or AWS KMS managed encryption keys are not replicated. This is because Amazon S3 doesn’t keep the encryption keys you provide after the object is created in the source bucket, so it cannot decrypt the object for replication.
Also, S3 will only copy those objects for which the owner has permissions for read objects and read ACLs. It is possible to set up cross-region replication on the source bucket owned by one account to replicate objects in a destination bucket owned by another account.
How to Set Up Cross-Region Replication
To set up cross-region replication, we need the source and destination buckets in different AWS regions. Then, we need to follow the below mentioned steps:
- Both the buckets must have versioning enabled.
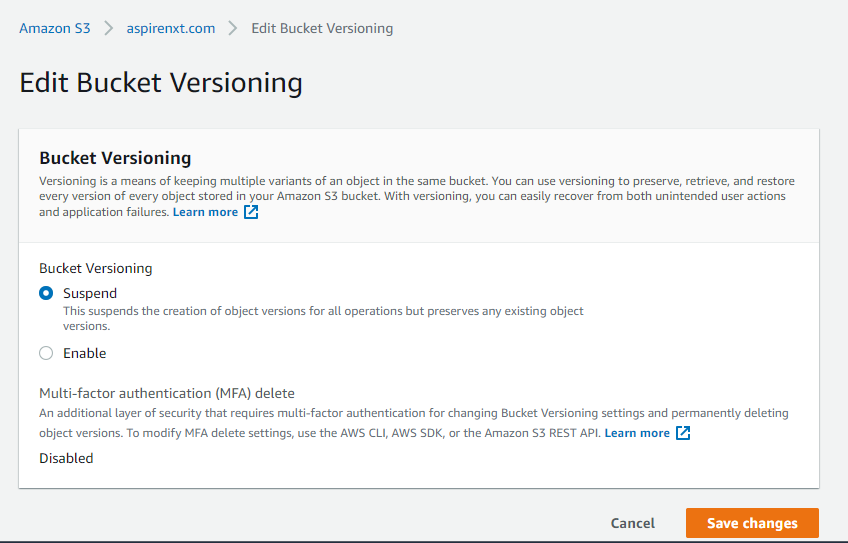
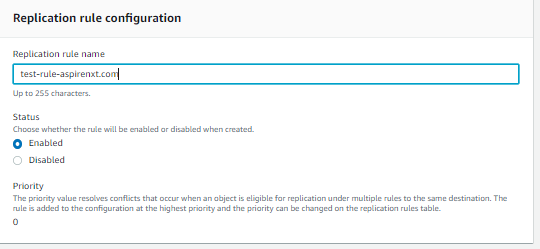
- Now, in the Management tab, to enable replication from the source to the target, create a rule by selecting Create a Replication Rule under Replication Rules. and enter a rule name.
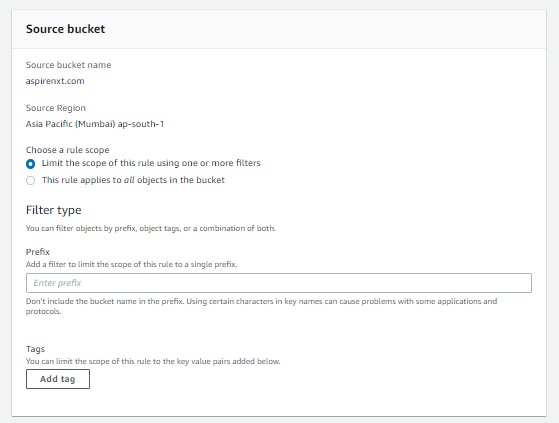
- Select the Source Bucket and its region. You can choose to replicate the entire bucket or just those objects with a specific prefix.
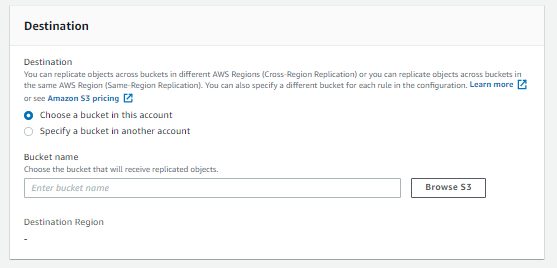
- Select a Destination Bucket and its region different than the Source Bucket Region. The Destination Region will appear when we select the destination bucket. For destination storage class, you can choose between different S3 storage types (e.g., Standard, Standard-Infrequent Access, Reduced Redundancy) and change the owner of the replicated object.
- A specific IAM role is required to replicate objects from the source to the destination bucket. If we select” Create new role,” AWS will automatically create the role with the appropriate policy.
Here is sample of what the policy looks like:

After the settings are saved, every object uploaded henceforth to the source bucket will be automatically replicated to the destination bucket.
Conclusion
The ability to replicate data to another region or data center is very important, either for performance optimization or as part of a quality disaster recovery plan that will increase the availability and reliability of the application. Either via S3 cross-region replication between AWS regions, from one data center to another, or between AWS regions and data centers for hybrid applications, S3 bucket replication is an essential feature to consider when developing an application and building its infrastructure.


